内存管理
Mar 19, 2025
21 mins read
内存回收OOM
malloc分配的是虚拟内存,而非物理内存。当这块虚拟内存被读写了的时候,CPU会访问这块虚拟内存,然后发现该虚拟内存没有被映射到物理内存,CPU就会产生缺页中断,进程从用户态 一> 内核态。
缺页中断处理函数(Page Fault Handler)会判断是否有空闲的物理内存,如果有,就直接分配物理内存,否则回收内存。
有两种回收内存的方式:后台内存回收(异步)、直接内存回收(如果后台回收跟不上进程内存申请的速度就会开始直接回收,这个过程是同步的,会阻塞进程执行)。
如果直接内存回收,仍旧不满足申请的内存大小,那么就会触发OOM(Out Of Memory)机制。
OOM机制会根据算法杀死一个占用物理内存最高的进程,如果还是无法满足,继续杀死进程,直到释放足够多的内存。
如何保护一个进程不被OOM杀掉呢?
Linux中通过oom_badness()对每个进程打分,得分最高的进程会被杀掉。得分机制:
- 进程所占用物理内存页面数量
- 每个进程的OOM校准值
oom_score_adj[-1000, 1000]
我们可以通过调整校准值来防止进程被OOM杀掉。比如说设置成-1000,无论如何都不会被杀掉。但是不建议将业务程序这样设置,因为如果某个业务程序发生内存泄漏,而又无法被杀掉,那么OOM会把其他进程都杀掉了。
文件页和匿名页
哪些内存会被回收?
文件页:内核缓存的文件数据(Cache)和内核缓存的磁盘数据(Buffer)都属于文件页。如果被应用程序修改过并且还没写入磁盘的数据叫做脏页。回收干净页的方式是直接释放内存,回收脏页的方式是先写回磁盘后再释放内存。
匿名页:没有磁盘这样的实际载体,比如栈和堆。这些内存不能直接释放,因为很可能会再次被访问。将不常访问的数据换出物理内存放到磁盘中的swap分区,如果需要访问,就从磁盘中读入内存(会发生缺页中断)而常访问的数据会在物理内存RAM / Cache / TLB——系统会根据数据的访问热度,在多个层次自动做缓存或常驻处理。
文件页是比如说我d盘里有一个文件然后程序去读取,读取之后可以丢掉因为磁盘里有这个东西,但是匿名页是没有实际载体,是在程序运行中分配的数据。
文件页和匿名页的回收都基于LRU算法。
回收内存除了回收干净页,都会发生磁盘 I/O的,这会影响系统性能。
可以申请虚拟内存超过物理内存吗?
在32位操作系统,进程最大只能申请3GB的虚拟内存。
在64位操作系统,进程最大可以申请128TB的虚拟内存。
所以如果想在4GB的物理内存空间上直接申请8GB的虚拟内存,在32位操作系统上会申请失败,而在64位会成功。
如果有Swap分区,即使物理内存只有4GB,进程也可以正常使用8GB的内存。
LRU预读失效
LRU预读失效怎么办?
如果应用程序想读取 0 - 3KB 范围内的数据,由于磁盘基本读写单位为 block(4KB),于是操作系统至少会读 0 - 4KB 的内容,但是由于空间局部性原理(靠近当前被访问数据的数据,在未来很大概率会被访问到),所以会把[4, 8],[8, 12]以及[12, 16]都加载到内存。
预读机制带来的好处是减少磁盘 I/O 次数,提高系统磁盘 I/O 吞吐量。
预读失效:就是这些被提前加载进来的页面没有被访问,相当于预读白做了。不会被访问的预读页却占用了 LRU 链表前排的位置,而末尾淘汰的页,可能是热点数据,这样就大大降低了缓存命中率。
想要避免预读失效,就要尽可能地保证预读的数据停留内存的时间要短,真正的热点数据尽可能久的留在内存。Linux操作系统就实现了两个LRU链表:活跃LRU链表(active_list)和非活跃LRU链表(inactive_list)。
预读页就只需要加入到 inactive list 区域的头部,当页被真正访问的时候,才将页插入 active list 的头部。
缓存污染
缓存污染怎么办?
虽然两个LRU链表可以解决预读失效的问题,但是还会存在缓存污染的问题。当批量读取数据时,如果数据被访问了一次就加入到LRU中,那么活跃链表中会一下子淘汰了很多热点数据,而那些被新加入的数据很长一段时间不会被访问,导致了整个LRU活跃链表被污染。等到下一次读到那些热点数据的时候,一下子发生了很多次磁盘I/O,性能急剧下降。
所以要想避免缓存污染,需要提高数据加入到活跃链表的门槛,保证在活跃链表中的数据不会被轻易替换掉。Linux操作系统中,当内存页被访问第二次才会将页从非活跃链表加入到活跃链表。
malloc(1024)是否会立刻占用物理内存?
不会,malloc仅修改进程的堆指针(通过brk和mmap),在虚拟地址空间中划出区域,物理内存尚未分配。当首次访问该内存时会触发缺页中断(page fault),然后内核才会分配物理页帧并建立页表映射。
内存泄漏&垃圾回收
内存泄漏:动态分配的内存但未及时释放 / 循环引用导致无法释放。
垃圾回收:系统自动检测并回收无用内存。基本思想:找出不可达对象(从根引用对象出发),释放内存空间。
GC是根据对象的指针指向去搜寻其他对象的。如果一个对象被其他对象通过指针/引用,那么它就是活动对象。反之,就是非活动对象需要被GC回收。
GC性能评判标准
评价 GC 算法的性能时,我们采用以下 4 个标准。
- 吞吐量 = 运行用户代码时间 /(运行用户代码时间 + 垃圾收集时间)
- 最大暂停时间:因为执行GC而暂停执行应用程序的最长时间。
- 堆使用效率 :单位时间内能使用的堆内存空间的大小
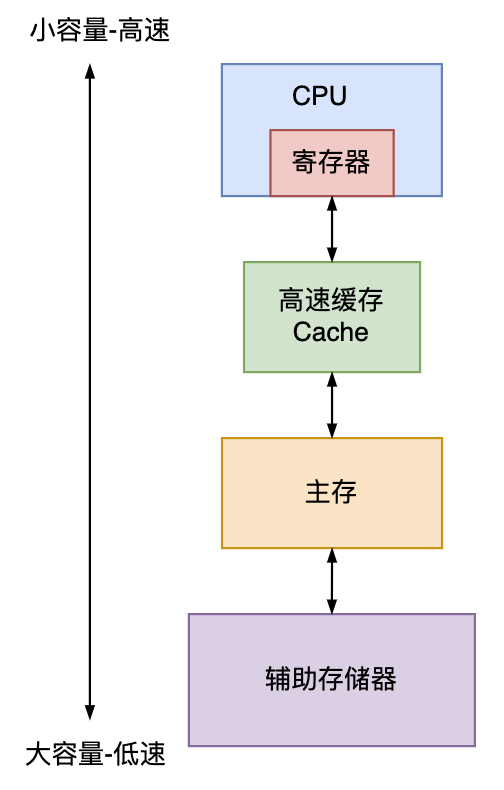
- 访问的局部性——计算机上有4种寄存器,分别是寄存器、缓存、内存、辅助存储器。越是高速的存储器容量越小,当CPU访问数据时,可能会因为预读机制将附近的数据读取到高速缓存中,这种内存空间中相邻的数据很可能存在连续访问因而带来访问效率提升的情况,称为“访问的局部性”。
最基本的3种垃圾回收方法:
标记-清除算法
从根对象开始标记可达对象,未标记的对象需要清除
标记阶段结束后的堆状态如图所示:
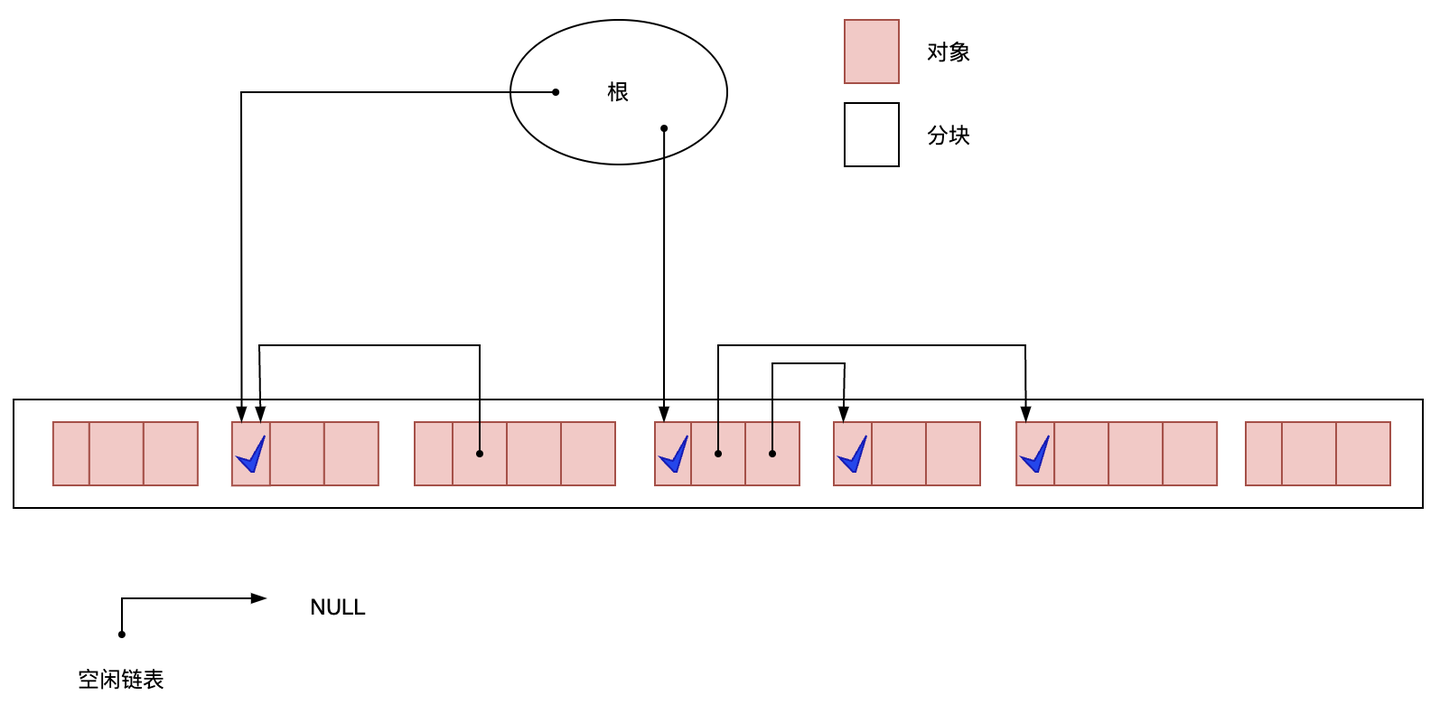
清除阶段会把非活动对象连接到空闲链表中。当程序需要分配新对象时会从空闲链表中搜索合适大小的块分配给新对象(分配)。顺便会将连续的空闲块合并方便后续大对象(合并)。
**缺点:**容易产生内存碎片、分配速度慢(每次分配都要遍历空闲链表去找足够大的分块)
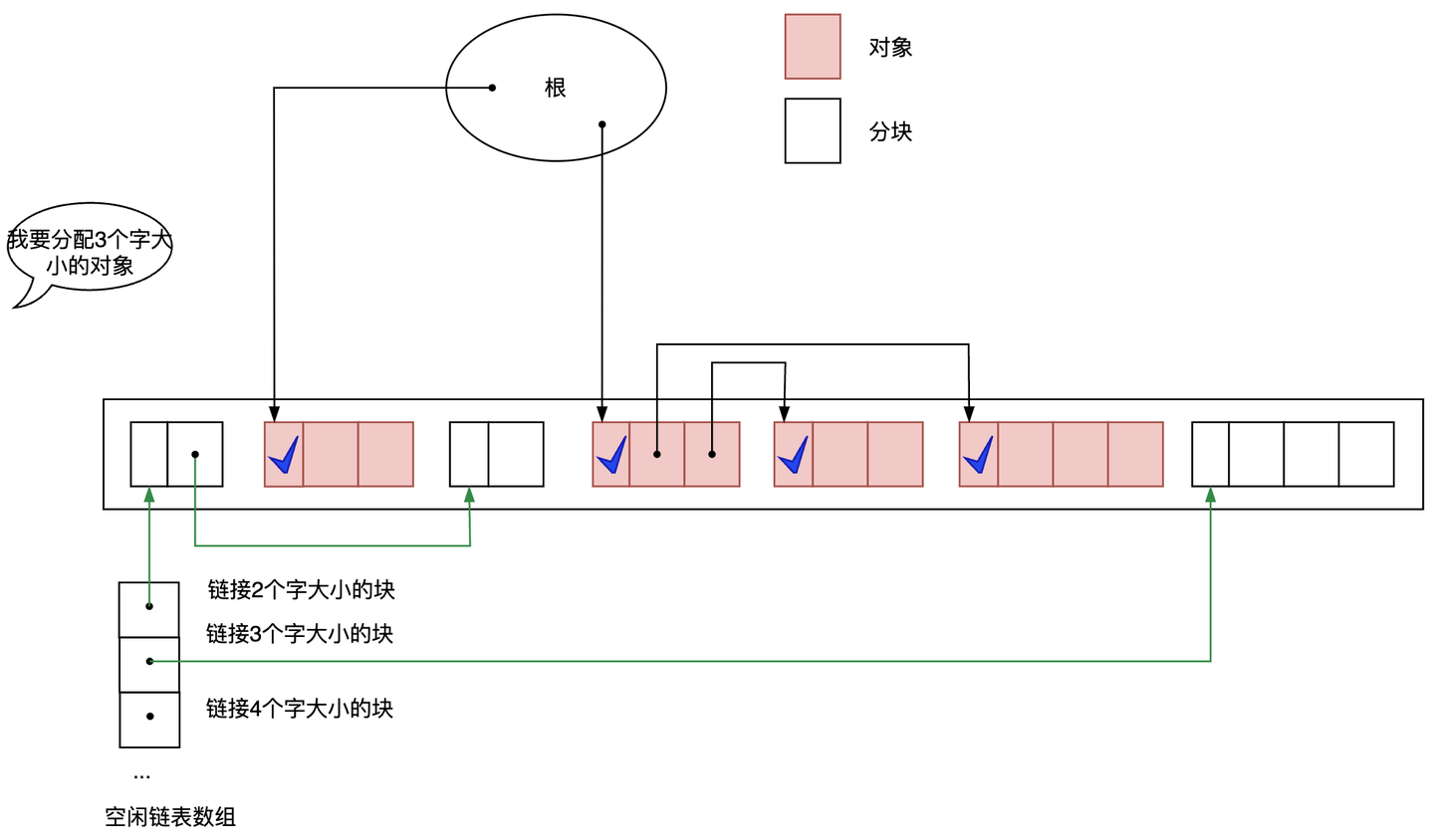
改进:多个空闲链表提升分配速度
Golang的内存分配就是这样实现的,根据不同规格大小的分块采用不同的链表管理。
引用计数法
每个对象维护引用计数,引用计数=0时进行回收。
**优点:**最大暂停时间短,可立马回收垃圾。
**缺点:**频繁的更新计数器处理繁重。计数器需要占用很多位,因为必须要数完堆中所有对象的引用数。无法回收循环引用。
改进:延迟引用计数法
采用一个零数表ZCT(Zero Count Table),即使引用数=0,程序也先不回收这个对象,而是等ZCT满了或者空闲链表为空了才去扫描ZCT。
GC复制算法
某个空间里的活动对象复制到其他空间,把原空间里的所有对象都回收掉。
将内存分为From空间和To空间,当 From 空间被完全占满时,GC 会将活动对象全部复制(而非转移,只是副本,From空间仍存在该对象)到 To 空间。当复制完成后,该算法会把 From 空间和 To 空间互换(因为不再需要From空间的对象了,所有活动对象都被转移到了To空间),GC 也就结束了。From 空间和 To 空间大小必须一致。这是为了保证能把 From 空间中的所有活动对象都收纳到 To 空间里。
GC复制算法目前查找引用对象使用的是深度优先搜索,算法过程建议参考知乎原文,链接在上方。
**优点:**吞吐量高,不会碎片化、高速分配、满足访问的局部性。
**缺点:**堆使用效率低下,需要递归复制子对象负担高,可能栈溢出。
**改进:**多空间复制算法,可以将堆N等分,其中部分空间执行GC复制算法,对剩下的空间执行GC标记-清除算法。
标记-压缩算法
GC 标记-压缩算法(Mark Compact GC)是将 GC 标记-清除算法与 GC 复制算法相结合的产物。压缩阶段不会改变对象的排列顺序,只是把对象按顺序从堆各处向左移动到堆的开头。 这样就缩小了它们之间的空隙, 把它们聚集到了堆的一端。
优点:可有效利用堆、没有碎片化问题。
缺点:必须对整个堆进行3次搜索,代价大。吞吐量不如其他算法。
分代收集
程序应用中的一个经验:大部分的对象在生成后马上就变成了垃圾, 很少有对象能活得很久。
分代垃圾回收(Generational GC),利用了该经验,在对象中导入了“年龄”的概念,经历过一次 GC 后活下来的对象年龄为 1 岁。
按对象存活时间分代。新生代使用复制算法,老年代使用标记压缩法。
分代垃圾回收算法把对分成了四个空间,分别是生成空间、2 个大小相等的幸存空间以及老年代空间。新生代对象会被分配到新生代空间,老年代对象则会被分配到老年代空间里。

2 个幸存空间和 GC 复制算法里的 From 空间、To 空间很像,我们经常只利用其中的一个。 在每次执行新生代 GC 的时候,活动对象就会被复制到另一个幸存空间里。在此我们将正在使用的幸存空间作为 From 幸存空间,将没有使用的幸存空间作为 To 幸存空间。
经过一定次数的存活,新生代会得到晋升,被复制到老年代空间中去。
缺点:不适合大部分对象存活较久的程序。对对象会活得很久的程序执行分代垃圾回收,就会产生以下两个问题:新生代GC所花费的时间增多,老年代GC频繁运行。
Sharing is caring!