Games104 AI
Dec 17, 2024
9 mins read
AI
导航
世界表达
地图——找到可通行区域,这个可通行区域针对不同NPC不同,比如说骑马可以越过去这个障碍。
Waypoint Network路点网络,首先会在地图上生成很多个点,这些点可以连成网络。像是地铁网络图,玩家要每一步去找离自己最近的点。现在游戏中用的很少了,很古老的方法。
Grid 地图分化为很多格子,它的好处是可以动态的更新(新的障碍出现,直接在网格中就可以呈现出),但是大的地图会有很多格子,性能不好;上下层结构,无法导航到桥上。
Navigation Mesh 缺点2D空间,难以拓展到三维。比如说在空中。
Sparse Voxel Octree 八叉树可以拓展到三维空间,但是寻路挺麻烦的。
寻路
所谓寻路,就是在网络上去找一条路径。
dfs bfs——比较费,因此引入了Dijkstra算法
A*算法 启发函数:过去花的成本+到目标点还要多少代价。f(n) = g(n) + h(n)
A*改进
1.我们可以将启发函数改为如下形式,即在预估函数前增加一个系数w,从而改变启发函数的权重。(动态加权,根据物品的重要性、数量、难度等其他因素)
$$ f ( n ) = g ( n ) + w ∗ h ( n ) $$引入跳点搜索(Jump Point Search)技术。跳点搜索通过检测直线路径上的阻塞点,直接跳过这些点,从而减少搜索空间。这种技术能够有效地剪枝,提高搜索效率。例如,在一个网格地图中,如果发现一个节点的邻居节点都是障碍物,就可以跳过这些邻居节点,直接搜索下一个可能的路径。这样可以大大减少搜索的节点数量,提高路径规划的效率。
平滑路径
Zigzag导致了不必要的多次转向。
HTN
像人类一样将大任务分解成多个子任务,从高层目标逐层展开到可执行的原子任务
架构组成:
l World State:AI对世界的抽象视角。
l Sensors:感知World State变化。
l HTN Domain:层次化任务结构(Task树)。
l Planner:根据任务树生成计划。
l Plan:具体执行步骤,执行完会更新World State。
任务类型:
Primitive Task:原子任务,可直接执行。
Compound Task:复合任务,包含多个方法,类似行为树中的Selector + Sequence。
示例:AI要解毒 → 可以选择制作药水或购买药水 → 使用药水。
Replanning触发条件:
- 没有可用计划。
- 当前计划完成或失败。
- World State发生变化。
比如说:AI需要一瓶药水解毒,它可以选择用足够的材料制作药水再使用药水,也可以花足够的钱去购买药水再使用药水。
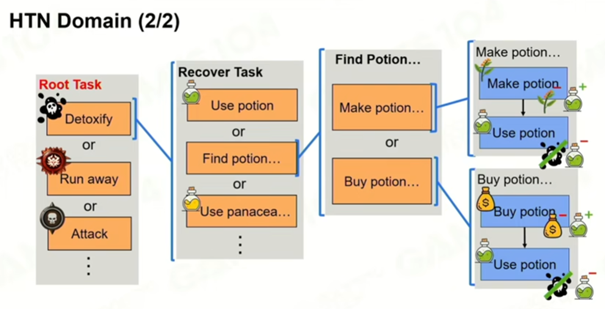
HTN相当于有一个Root,在进行任务的时候选择目标Task,然后一层层的展开,最后选择一个PrimitiveTask,每个任务都会被展开成更具体的子任务,直到最终可以通过执行原子操作来完成。完成一系列执行之后会更新World State的属性(更改世界的状态)。
Replanning(重新规划)是指在计划执行过程中,由于环境或任务状态的变化,需要重新生成或调整任务计划的过程。有三种情况:没有这个计划、当前plan已经完成或失败、
感知到了World State改变。
和行为树很像,执行效率高于行为树,因为每次都要遍历整棵树。HTN大部分逻辑是写死的,可能因为环境改变导致有些计划过时了没办法被执行,并且如果高度不确认性的环境HTN如果逻辑非常紧密会适得其反。
GOAP 目标导向AI系统
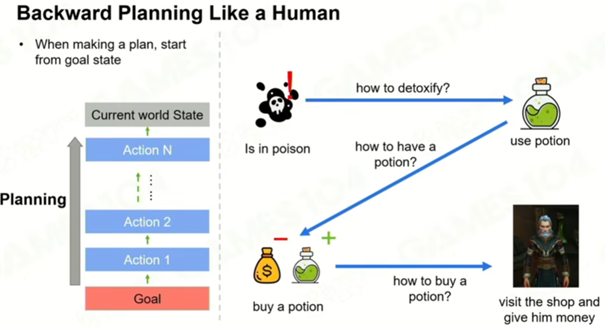
类似人类倒叙的思考
比如说我要完成解毒修改这个WorldState,那么我就需要一瓶药水,需要把这个state和Plan加到堆栈中,然后我要获取这瓶药水,继续把State和Plan加入到堆栈中,直到能满足这个State,弹出堆栈。最后完成目标会使所有的栈都清空。
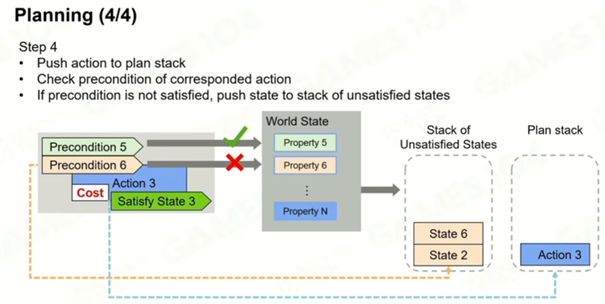
目标集 Goal Set 各个目标有优先级
行为集 Action Set 改变世界状态数据的行为
Goap 会让AI变得更活,将目标和行为分开,能够动态组合给出不同方案,缺点是需要大量计算(A*和动态规划图的结构)。
MCTS 蒙特卡洛树搜索
AlphaGo围棋就是使用蒙特卡洛树搜索
Sharing is caring!